
목록Computer/Pandas (20)
BASHA TECH
피봇테이블(pivot table)이란 데이터 열 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하여 펼쳐놓은 것을 말한다. 판다스는 피봇테이블을 만들기 위한 pivot 메서드를 제공한다. 첫번째 인수로는 행 인덱스로 사용할 열 이름, 두번째 인수로는 열 인덱스로 사용할 열 이름, 그리고 마지막으로 데이터로 사용할 열 이름을 넣는다. 판다스는 지정된 두 열을 각각 행 인덱스와 열 인덱스로 바꾼 후 행 인덱스의 라벨 값이 첫번째 키의 값과 같고 열 인덱스의 라벨 값이 두번째 키의 값과 같은 데이터를 찾아서 해당 칸에 넣는다. 만약 주어진 데이터가 존재하지 않으면 해당 칸에 NaN 값을 넣는다. pivot_table¶ pivot_table Pandas는 pivot 명령과 groupb..
1. 데이터 셋 확인 - 데이터가 어떻게 구성되어있는지 확인한다. - null data가 존재한다면 확인 후 수정해야함. 2. 탐색적 데이터 분석 (EDA: Exploratory Data Analysis) - 여러 feature들을 개별적으로 분석하고, feature들 간의 상관관계를 확인한다. - 여러 시각화 툴을 이용하여 insight를 얻기. 3. 특성 공학 (Feature Engineering) - 모델을 만들기 전에 모델의 성능을 높힐 수 있도록 feature들을 engineering하기. - engineering 하는 방법에는 one-hot enconding, class 나누기, 구간으로 나누기, 텍스트 데이터 처리 등이 있다. 4. 모델 개발 및 학습 - sklearn, keras을 사용해 ..
 Predict survival on the Titanic 타이타닉 생존자 예측 예제 2
Predict survival on the Titanic 타이타닉 생존자 예측 예제 2
##### Modeling => 학습 터미널 (pandas-dev) D:\big15\pandas-dev>pip install scikit-learn Collecting scikit-learn Downloading scikit_learn-1.1.2-cp38-cp38-win_amd64.whl (7.3 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.3/7.3 MB 26.1 MB/s eta 0:00:00 Collecting joblib>=1.0.0 Downloading joblib-1.2.0-py3-none-any.whl (297 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 298.0/298.0 kB 9.0 MB/s eta 0:00:00 ..
 Predict survival on the Titanic 타이타닉 생존자 예측 예제 1
Predict survival on the Titanic 타이타닉 생존자 예측 예제 1
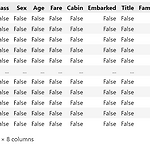
#### 1. 데이터 로딩 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 학습 데이터, 테스트 데이터를 로딩 => DataFrame으로 만들거임 train = pd.read_csv('../data/titanic/train.csv') test = pd.read_csv('../data/titanic/test.csv') #### 2. Exploratory data analysis (EDA: 탐색적 데이터 분석) - 탐색적 데이터 분석 : 데이터 탐색해서 데이터 구조와 의미 파악 train.head(5) 데이터 정리 - PassengerId : 고객 번호 - Survived : 생존 여부,..
 셀프 주유소 가격 분석
셀프 주유소 가격 분석
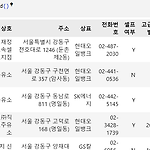
# 서울시 구별 주유소 가격 정보 가져오기 # URL : https://www.opinet.co.kr/searRgSelect.do driver = webdriver.Chrome('../driver/chromedriver.exe') driver.get('https://www.opinet.co.kr/searRgSelect.do') # //*[@id="SIGUNGU_NM0"] # 구가 들어있는 select box 선택 gu_list_raw = driver.find_element(By.XPATH, '//*[@id="SIGUNGU_NM0"]') print(gu_list_raw) # ctrl+shift+'-' 셀을 쪼개줌 gu_list = gu_list_raw.find_elements(By.TAG_NAME,'opt..
terminal> (pandas-dev) D:\big15\pandas-dev>pip install selenium Collecting selenium Downloading selenium-4.5.0-py3-none-any.whl (995 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 995.2/995.2 kB 15.9 MB/s eta 0:00:00 Collecting urllib3[socks]~=1.26 Downloading urllib3-1.26.12-py2.py3-none-any.whl (140 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 140.4/140.4 kB 2.1 MB/s eta 0:00:00 Requirement alre..
D:\big15\pandas-dev>D:/Anaconda3/Scripts/activate (base) D:\big15\pandas-dev>conda activate pandas-dev (pandas-dev) D:\big15\pandas-dev>pip install bs4 Collecting bs4 Downloading bs4-0.0.1.tar.gz (1.1 kB) Preparing metadata (setup.py) ... done Collecting beautifulsoup4 Downloading beautifulsoup4-4.11.1-py3-none-any.whl (128 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 128.2/128.2 kB 3.8 MB/s eta..
12-1. datetime 오브젝트 - datetime 오브젝트로 변환하기 - to_datetime 메소드 - 시간형식 지정자 - datetime 오브젝트로 변환하기 - read_csv 메소드 - datetime 오브젝트에서 날짜 정보 추출하기 - dt 접근자 사용하기 12-2. 사례별 시계열 데이터 계산하기 - datetime 오브젝트와 인덱스 - DatetimeIndex - 시간 간격과 인덱스 - TimedeltaIndex - 시간 범위와 인덱스 - 시간 범위 수정하고 데이터 밀어내기 - shift 메소드 data_df=pd.DataFrame({ 'A' : ['A0','A1','A2'] , 'B' : ['B0','B1','B2'] , 'C' : ['C0','C1','C2'] }) data_df dat..
11-1. 데이터 집계 - 데이터 집계하기 - groupby 메소드 - 분할-반영-결합 과정 살펴보기 - groupby 메소드 - groupby 메소드와 함께 사용하는 집꼐 메소드 - agg 메소드로 사용자 함수와 groupby 메소드 조합하기 - 여러 개의 집계 메소드 한번에 사용하기 11-2. 데이터 변환 - 표준점수 계산하기 - 누락값을 평균값으로 처리하기 11-3. 데이터 필터링 11-4. 그룹 오브젝트 - 그룹 오브젝트 살펴보기 - 한 번에 그룹 오브젝트 계산하기 - 그룹 오브젝트 활용하기 - 여러 열을 사용해 그룹 오브젝트 만들고 계산하기 # apply method import numpy as np import pandas as pd df = pd.read_csv('../data/gapmind..
10-1. 간단한 함수 만들기 10-2. apply 메소드 사용하기 - 기초 10-3. apply 메소드 사용하기 - 고급 # apply method import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # titanic data loading titanic = sns.load_dataset('titanic') titanic.head() titanic.info() titanic.isnull().sum()