
BASHA TECH
Predict survival on the Titanic 타이타닉 생존자 예측 예제 2 본문
728x90
##### Modeling => 학습
터미널
(pandas-dev) D:\big15\pandas-dev>pip install scikit-learn
Collecting scikit-learn
Downloading scikit_learn-1.1.2-cp38-cp38-win_amd64.whl (7.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.3/7.3 MB 26.1 MB/s eta 0:00:00
Collecting joblib>=1.0.0
Downloading joblib-1.2.0-py3-none-any.whl (297 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 298.0/298.0 kB 9.0 MB/s eta 0:00:00
Requirement already satisfied: scipy>=1.3.2 in d:\anaconda3\envs\pandas-dev\lib\site-packages (from scikit-learn) (1.7.3)
Requirement already satisfied: numpy>=1.17.3 in d:\anaconda3\envs\pandas-dev\lib\site-packages (from scikit-learn) (1.21.5)
Collecting threadpoolctl>=2.0.0
Downloading threadpoolctl-3.1.0-py3-none-any.whl (14 kB)
Installing collected packages: threadpoolctl, joblib, scikit-learn
Successfully installed joblib-1.2.0 scikit-learn-1.1.2 threadpoolctl-3.1.0from sklearn.neighbors import KNeighborsClassifier # KNN / 여기서 K는 개수를 의미
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVCfrom sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score # 분류에서 정확도를 추정할 때 사용
k_fold = KFold(n_splits=10, shuffle=True, random_state=42)KNN
# KNN : 성능이 안 좋다. 속도가 느림.
clf = KNeighborsClassifier(n_neighbors=13)
scoring = 'accuracy' # 평가방법(지표) => 정확도
score = cross_val_score(
clf # 학습할 모델
, train_X # 학습할 데이터
, train_y # 학습 데이터 답
, cv = k_fold # cross_valiation의 갯수(cnt)
, n_jobs = -1 # cpu의 core 개수 지정 (병렬 처리가 된다) -1: 코어를 다 써라
, scoring=scoring # 평가 방법(지표)
)
print(score)
print(round(np.mean(score)*100, 2)) # 평균 정확도Decision Tree
# Decision Tree
clf = DecisionTreeClassifier()
scoring = 'accuracy'
score = cross_val_score(
clf
, train_X
, train_y
, cv = k_fold
, n_jobs = -1
, scoring=scoring
)
print(score)
print(round(np.mean(score)*100,2))Random Forest
# Random Forest
clf = RandomForestClassifier(n_estimators=13)
scoring = 'accuracy'
score = cross_val_score(
clf
, train_X
, train_y
, cv = k_fold
, n_jobs = -1
, scoring=scoring
)
print(score)
print(round(np.mean(score)*100,2))SVC
# SVC
clf = SVC()
scoring = 'accuracy'
score = cross_val_score(
clf
, train_X
, train_y
, cv = k_fold
, n_jobs = -1
, scoring=scoring
)
print(score)
print(round(np.mean(score)*100,2))# NaN값 처리 과정
test_X.isnull().sum()
test[test['Fare'].isnull()]
test_X[test_X['Fare'].isnull() | test_X['Title'].isnull()]
test_X[test_X['Fare'].isnull()]['Fare'] = 0
test_X[test_X['Fare'].isnull()]
test_X[test_X['Fare'].isnull()]['Fare']
test_X[test_X['Fare'].isnull()]['Fare'] = 0.0
test_X.loc[test_X['Fare'].isnull(),'Fare']
test_X.loc[test_X['Fare'].isnull(),'Fare'] = 0
test_X[test_X['Fare'].isnull()]
test_X.loc[test_X['Title'].isnull(),'Title']
test_X.loc[test_X['Title'].isnull(),'Title'] = 0test_X.isnull()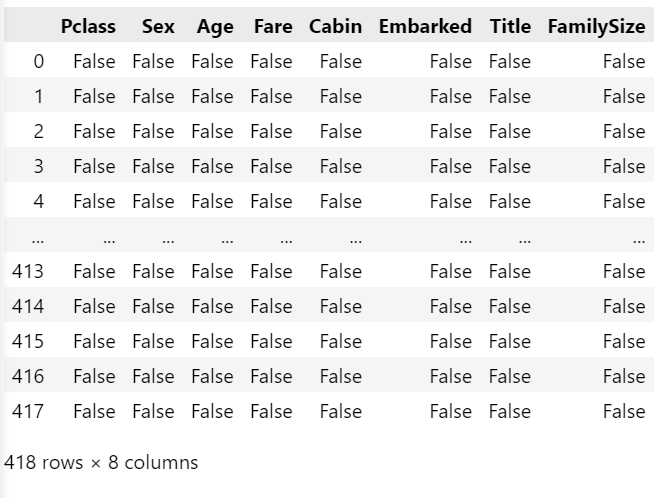
# Testing
clf = SVC()
clf.fit(train_X, train_y) # 학습을 시킴 => 학습된 식이 나옴 => 그것을 모델이라 함
test_X = test.drop('PassengerId', axis=1)
test_X.loc[test_X['Fare'].isnull(),'Fare'] = 0
test_X.loc[test_X['Title'].isnull(),'Title'] = 0
prediction = clf.predict(test_X)prediction
submission = pd.DataFrame({
'PassengerId' : test['PassengerId']
, 'Survived' : prediction
})
submission.to_csv('../data/titanic/assignments/submission.csv', index=False) # submission.csv을 kaggle에 올림import picklepickle 모듈
일반 텍스트를 파일로 저장할 때는 파일 입출력을 이용한다. 하지만 리스트나 클래스같은 텍스트가 아닌 자료형은 일반적인 파일 입출력 방법으로는 데이터를 저장하거나 불러올 수 없다. 파이썬에서는 이와 같은 텍스트 이외의 자료형을 파일로 저장하기 위하여 pickle이라는 모듈을 제공한다.
# save
with open(file='../data/titanic/assignments/titanic_sub1.pickle', mode='wb') as f:
pickle.dump(submission, f, pickle.HIGHEST_PROTOCOL)
# load
with open('../data/titanic/assignments/titanic_sub1.pickle', mode='rb') as f:
submission = pickle.load(f)submission
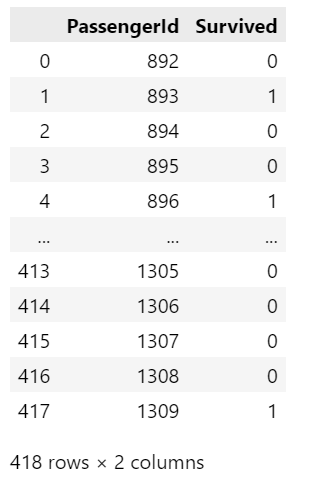
성공적으로 저장 됨.
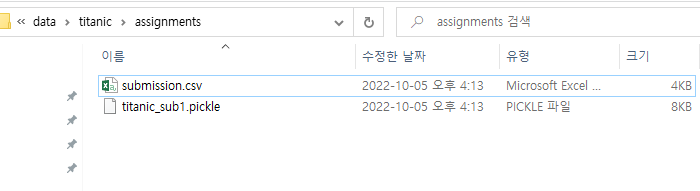
해당 csv를 제출
0.77033초 걸린다.
728x90
반응형
'AI > Pandas' 카테고리의 다른 글
| pivot, groupby (1) | 2022.10.05 |
|---|---|
| 데이터 분석 하는 과정 정리 (1) | 2022.10.05 |
| Predict survival on the Titanic 타이타닉 생존자 예측 예제 1 (1) | 2022.10.04 |
| 셀프 주유소 가격 분석 (1) | 2022.10.04 |
| 네이버 매크로 예제 (0) | 2022.10.04 |
'AI/Pandas' Related Articles
more


Comments