
BASHA TECH
셀프 주유소 가격 분석 본문
728x90
# 서울시 구별 주유소 가격 정보 가져오기
# URL : https://www.opinet.co.kr/searRgSelect.do
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get('https://www.opinet.co.kr/searRgSelect.do')# //*[@id="SIGUNGU_NM0"]
# 구가 들어있는 select box 선택
gu_list_raw = driver.find_element(By.XPATH, '//*[@id="SIGUNGU_NM0"]')
print(gu_list_raw)
# ctrl+shift+'-' 셀을 쪼개줌gu_list = gu_list_raw.find_elements(By.TAG_NAME,'option')
gu_listgu_names = [option.get_attribute('value') for option in gu_list]
gu_namesgu_names.remove('')
gu_names# 중랑구가 선택되어있는지 확인 테스트
# 구가 들어있는 select Box 선택
elem_gu = driver.find_element(By.ID,'SIGUNGU_NM0')
# 중랑구 선택
elem_gu.send_keys(gu_names[-1])
# 변경 확인# 조회 버튼 클릭
# 조회 버튼 선택 => XPATH, # 클릭
xpath = '//*[@id="searRgSelect"]'
elem_search = driver.find_element(By.XPATH, xpath).click()
# 클릭# 엑셀 저장 버튼 클릭
# 버튼 선택, 클릭
xpath = '//*[@id="glopopd_excel"]'
driver.find_element(By.XPATH,xpath).click()gu_names# 전체 구 데이터 추출
import time
from tqdm import tqdm
for gu in tqdm(gu_names):
elem = driver.find_element(By.ID, 'SIGUNGU_NM0')
elem.send_keys(gu) # 검색하고자 하는 구 이름 서버로 전송
time.sleep(2) # 2초간 결과를 기다린다.
# 조회 버튼 클릭
xpath = '//*[@id="searRgSelect"]'
elem_search = driver.find_element(By.XPATH, xpath).click()
time.sleep(1)
# 엑셀 저장 버튼 클릭
xpath = '//*[@id="glopopd_excel"]'
driver.find_element(By.XPATH,xpath).click()
time.sleep(1)import numpy as np
import pandas as pd
from glob import globglob('../data/지역*.xls') # 문자열에 대괄호가 쌓여있으니 => 리스트stations_files = glob('../data/지역*.xls')terminal>>
(pandas-dev) D:\big15\pandas-dev>pip install xlrd
Collecting xlrd
Downloading xlrd-2.0.1-py2.py3-none-any.whl (96 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 96.5/96.5 kB 2.8 MB/s eta 0:00:00
Installing collected packages: xlrd
Successfully installed xlrd-2.0.1pandas >
tmp_raw = []
for file_name in stations_files:
tmp_df = pd.read_excel(file_name, header=2)
tmp_raw.append(tmp_df)tmp_raw[0].head()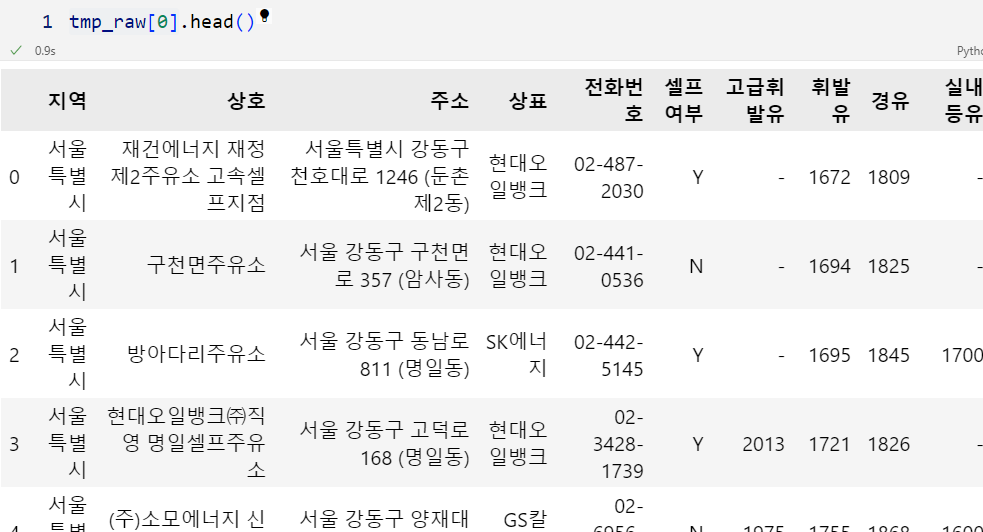
# dataframe 합치기 => concat
# dataframe 연결(join) => merge : 값으로 join 하는 것
station_raw = pd.concat(tmp_raw)
station_raw.info()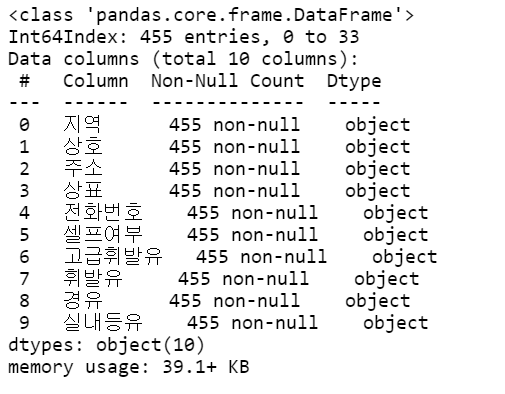
station_raw.head()# 2018년 데이터
stations_files = glob('../data/drive-download-20220930T010652Z-001/지역*.xls')
tmp_raw = []
for file_name in stations_files:
tmp_df = pd.read_excel(file_name, header=2)
tmp_raw.append(tmp_df)
station_raw = pd.concat(tmp_raw)
station_raw.info()이건 그냥 나 혼자 돌려봤다..
# 데이터 정리
# 상호, 주소, 휘발유, 셀프여부, 상표
stations_df = pd.DataFrame({
'상호' : station_raw['상호'] # Series
, '주소' : station_raw['주소']
, '가격' : station_raw['휘발유']
, '셀프' : station_raw['셀프여부']
, '상표' : station_raw['상표']
})
stations_df.head()stations_df.info()stations_df['주소'][0] # Seriesstations_df.iloc[:1,1]stations_df.iloc[0,1]stations_df.iloc[0,1].split()[1][-1] == '구'# 주소에서 구 추출
stations_df['구'] = [addr.split()[1] for addr in stations_df['주소']]
stations_df['구']stations_df['구'].unique()
# 이상한 값이 없는 지 확인 null이 있거나 NaN이 있거나 이상한 구가 있지 않은 걸 확인 할 수 있음len(stations_df['구'].unique()) # 데이터가 맞는지 검증해야 함. => 25개 모두 나옴~stations_df['가격']# '-' : 현재 가격을 입력하지 않은 주유소 확인
stations_df[stations_df['가격']=='-']# 가격이 없는 주유소 제외하고 새로운 데이터프레임을 생성 => boolean indexing 사용
stations_df = stations_df[stations_df['가격'] != '-']stations_df[stations_df['가격']=='-'] # 가격이 없는 주유소를 제외해서 결과값이 나오지 않는다# 가격을 숫자 (실수) => astype()
stations_df['가격'] = [float(price) for price in stations_df['가격']]stations_df.info()이건 내가 astype으로 코딩해봤다.
stations_df.astype({'가격':'float'})
stations_df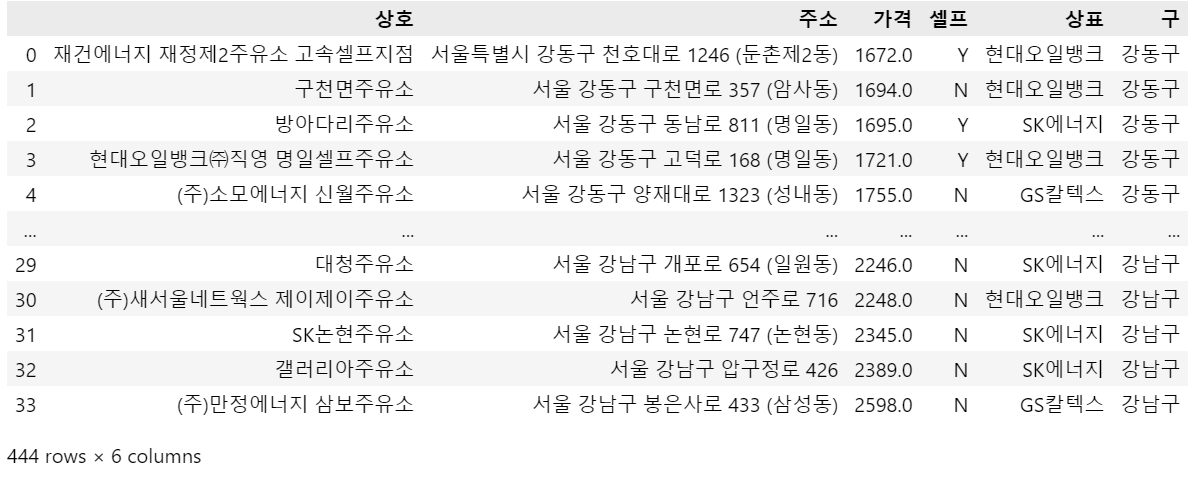
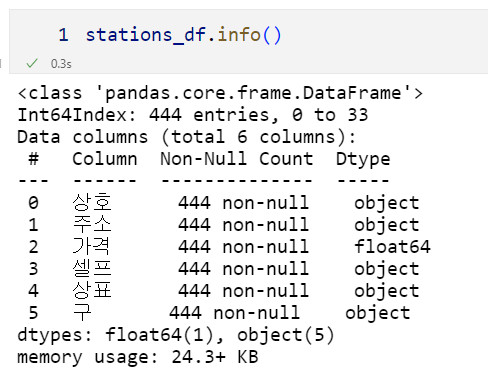
stations_df.reset_index(inplace=False).head()stations_df.reset_index(inplace=True)stations_df.head()del stations_df['index']
stations_df.head()# 차트 (EDA) : Exploratory Data Analysis 탐색적 데이터 분석
# 셀프주유소 가격 분석 : 셀프인 주유소랑 셀프가 아닌 주유소를 분석함
from tkinter.font import families
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc # rc: resource manager(환경)
# mac 기준 한글 처리 : 맥이 조금 간결하다.
# rc('font', family='AppleGothic') # 한글이 추가된다. 이거 안 하면 한글 깨짐
# window 10 기준 한글 처리
path = 'c:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name) #family => 글꼴
stations_df.columns# 셀프주유소(기준) 가격 분석 => DataFrame => boxplot()
stations_df.boxplot(
column='가격'
, by='셀프'
, figsize=(12,8) # tuple로 주기
# 그래프 내에 초록색 바 => 중앙값
)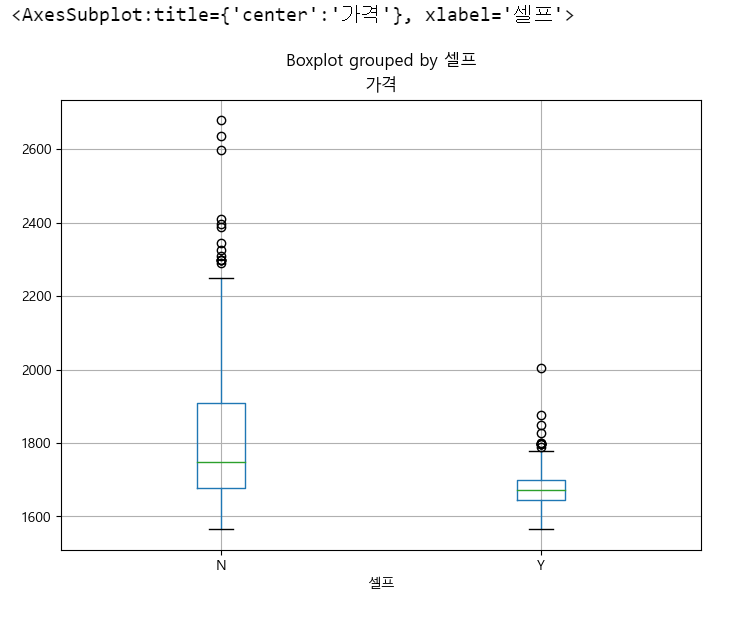
# 2600원이 넘어가는 주유소 데이터 추출해보기 => boolean 색인 활용
stations_df[stations_df['가격'] > 2550]
# quantile() => 자료 크기 순서에 따른 위치값 : 분위수
# 상표 별, 셀프 가격 분석 => boxplot으로 구현해보자!
plt.figure(figsize=(8,6))
sns.boxplot(
data = stations_df
, x = '상표'
, y = '가격'
, hue = '셀프'
, palette='Set1' # 색을 palette로 줄 수 있다
)
plt.show()
# sk에너지가 가장 비싸다! 알뜰 주유소가 가장 쌈..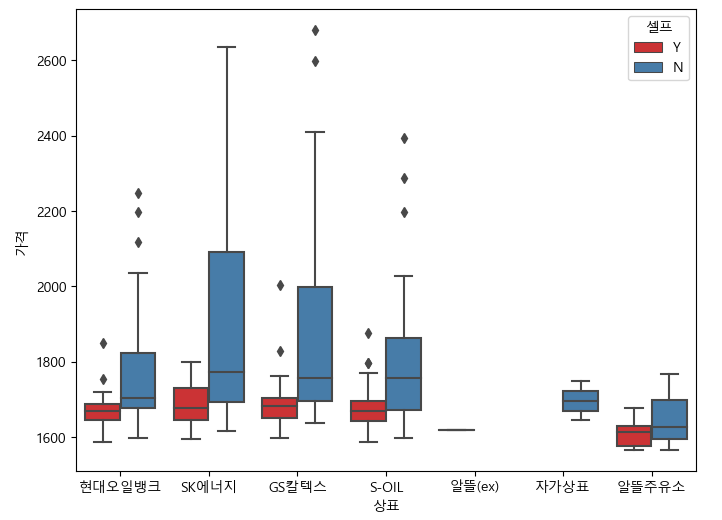
# 가격 상하위 10개씩 처리
stations_df.sort_values(by='가격', ascending=False).head(10) # Decencing됨
# 서계 주유소가 가장 비싸다!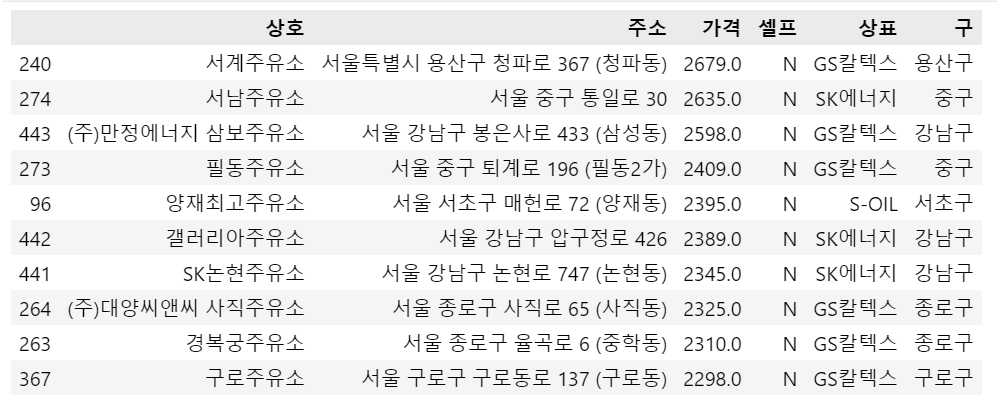
# 가격 하위 10개
stations_df.sort_values(by='가격', ascending=True).head(10)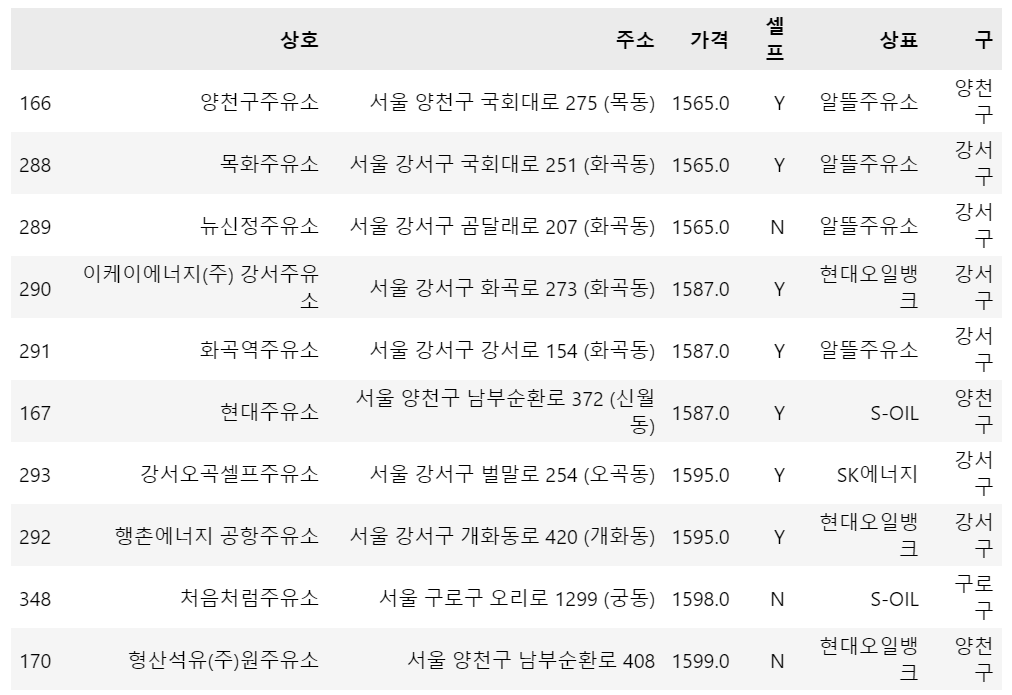
2022년 10월 4일 기준, 양천구 주유소가 서울시에서 가장 주유 가격이 가장 싸네요!
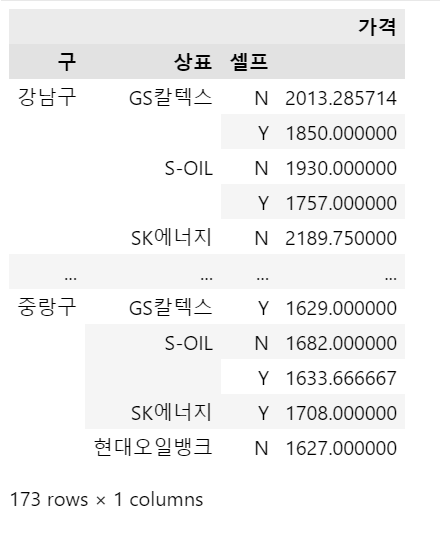
# 구별 가격 평균
pd.pivot_table( # pivot과 pivot_table의 차이 비교해보기
data=stations_df
, index=['구', '상표', '셀프'] # DataFrame임
, values=['가격']
, aggfunc=np.mean
)
# 상표 별, 셀프 가격 분석 => boxplot으로 구현해보자!
plt.figure(figsize=(18,6))
sns.boxplot(
data = stations_df
, x = '구'
, y = '가격'
, hue = '상표'
, palette='Set3' # 색을 palette로 줄 수 있다
)
plt.show()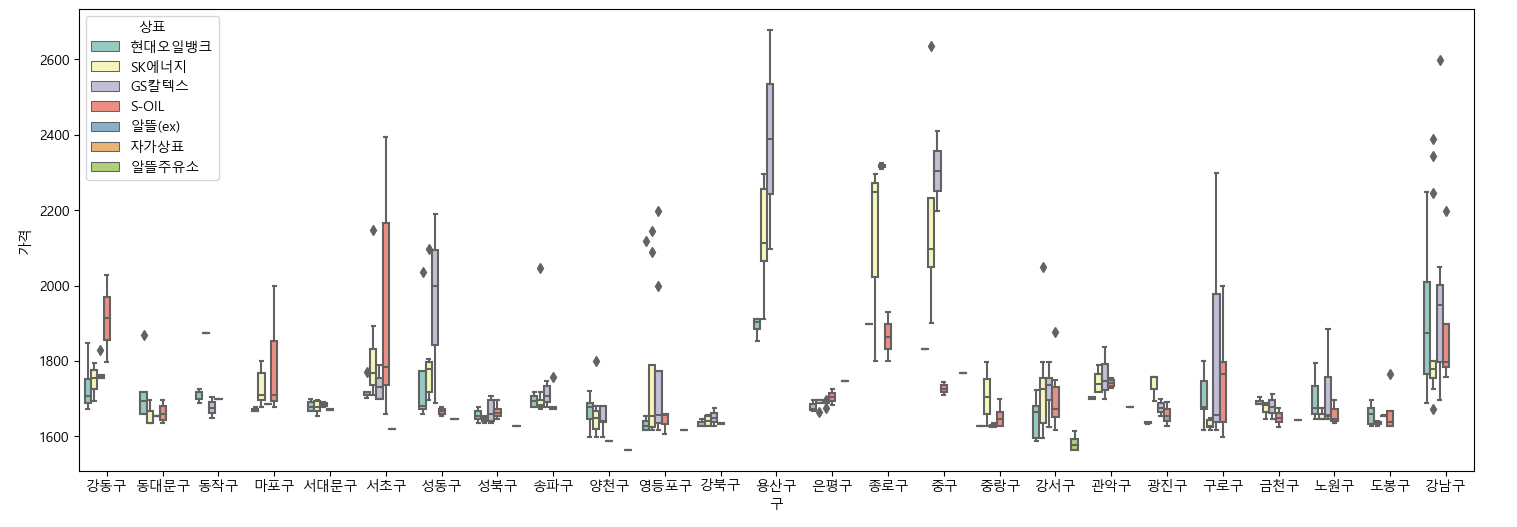
driver.close()728x90
반응형
'Computer > Pandas' 카테고리의 다른 글
| Predict survival on the Titanic 타이타닉 생존자 예측 예제 2 (0) | 2022.10.05 |
|---|---|
| Predict survival on the Titanic 타이타닉 생존자 예측 예제 1 (1) | 2022.10.04 |
| 네이버 매크로 예제 (0) | 2022.10.04 |
| 시카고 맛집 분석 예제 (1) | 2022.09.30 |
| Ch12. 시계열 데이터 (0) | 2022.09.29 |
'Computer/Pandas' Related Articles
more


Comments