
BASHA TECH
Ch05. 데이터 연결하기 본문
728x90
5-1. 분석하기 좋은 데이터
- 분석하기 좋은 데이터란?
5-2. 데이터 연결 기초
- 행이 1개라도 반드시 데이터 프레임에 담아 연결해야 합니다.
- 다양한 방법으로 데이터 연결하기
5-3. 데이터 연결 마무리
merge는 default가 inner join
concat은 default가 outer join
range는 잘 안 씀.
# concat() => 데이터 프레임 연결
# 데이터 읽기
import pandas as pd
df1 = pd.read_csv('../data/concat_1.csv')
df2 = pd.read_csv('../data/concat_2.csv')
df3 = pd.read_csv('../data/concat_3.csv')
df1.head()
df2.head()
df3.head()
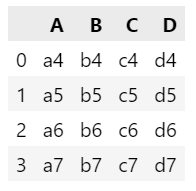

row_concat = pd.concat([df1, df2, df3])
row_concat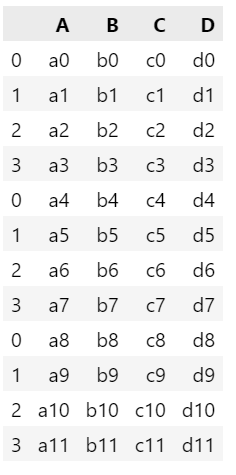
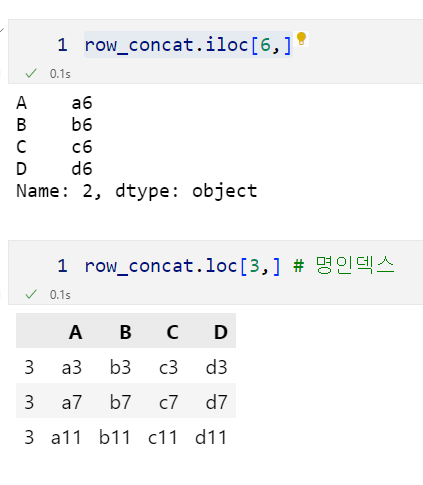
row_concat.iloc[6,]
row_concat.loc[3,] # 명인덱스
# Series 생성
new_row_series = pd.Series(['n1','n2','n3','n4'], name='A')
new_row_series
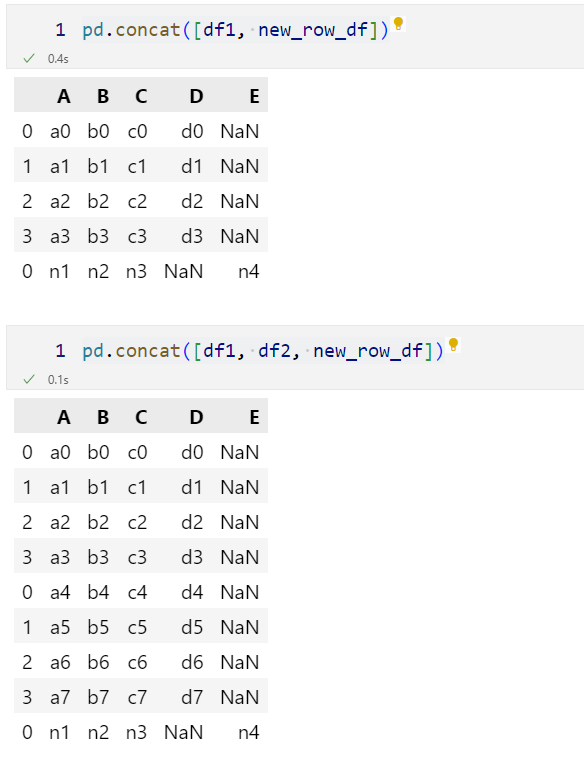
pd.concat([df1, new_row_series])
df1


new_row_series.name='E'
new_row_series
pd.concat([df1, new_row_series])
new_row_series


new_row_df = pd.DataFrame(
[['n1','n2','n3','n4']]
)
new_row_df # 컬럼 명을 지정하지 않으면 0, 1, 2, 3으로 나온다new_row_df = pd.DataFrame(
[['n1','n2','n3','n4']]
, columns=['A','B','C','E']
)
new_row_df
df1.append(df2)
df1.append(new_row_df)



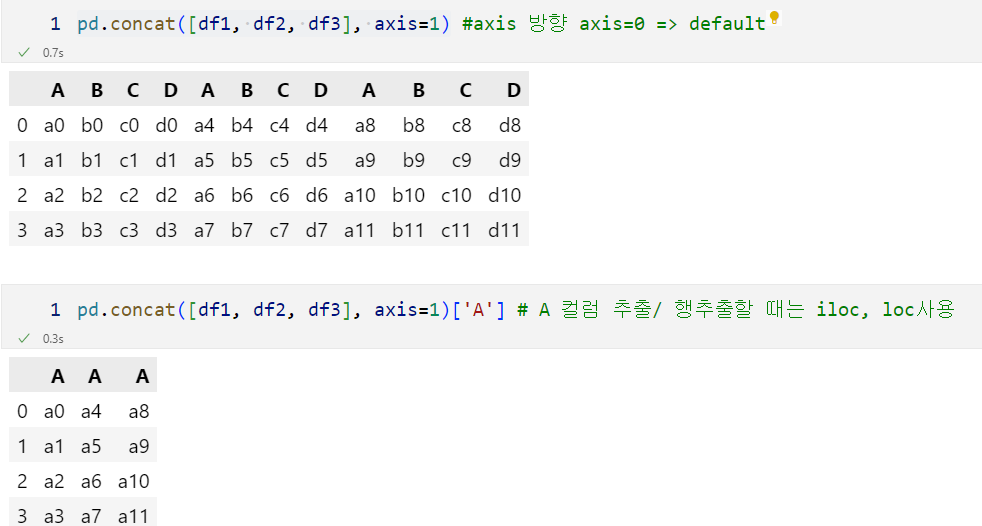

df1.columns=['A','B','C','D']
df2.columns=['E','F','G','H']
df3.columns=['A','C','F','H']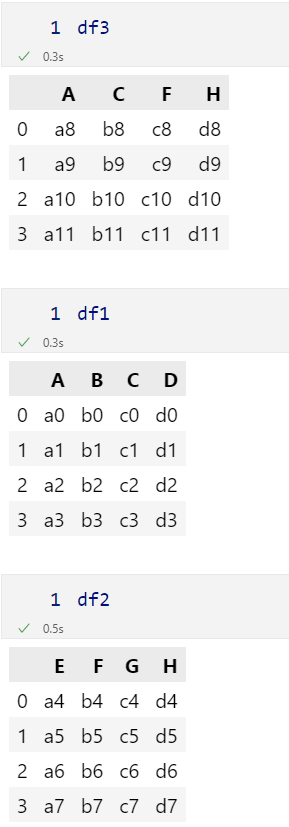
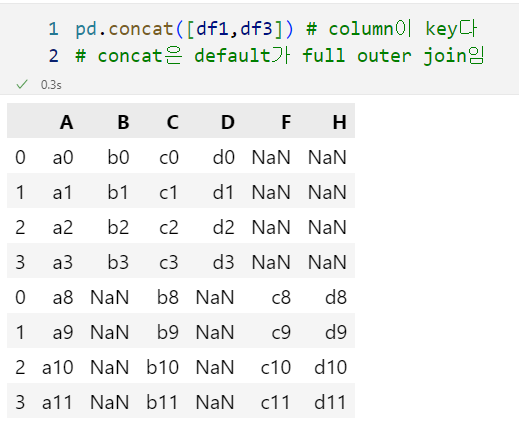






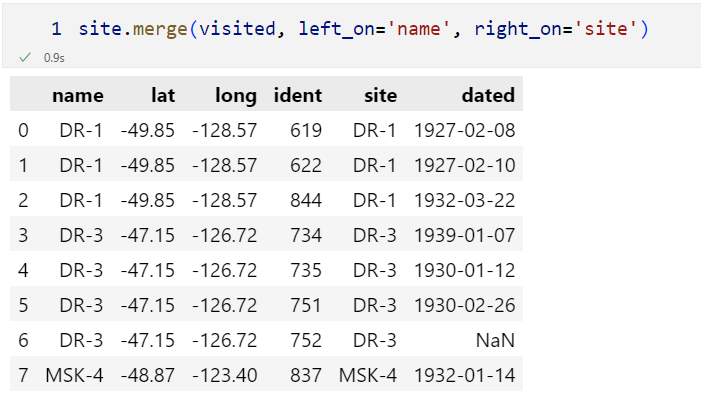
df1 = pd.DataFrame(
{
'key' : ['a','b']
, 'A' : ['a0','b0']
}
)
df1
------------------------
df2 = pd.DataFrame(
{
'key' : ['a','c']
, 'A' : ['a1','b2']
}
)


df1.merge? # parameter 확인
Output exceeds the size limit. Open the full output data in a text editor
Signature: df1.merge( right: 'DataFrame | Series',
how: 'str' = 'inner',
on: 'IndexLabel | None' = None,
left_on: 'IndexLabel | None' = None,
right_on: 'IndexLabel | None' = None,
left_index: 'bool' = False,
right_index: 'bool' = False,
sort: 'bool' = False,
suffixes: 'Suffixes' = ('_x', '_y'),
copy: 'bool' = True,
indicator: 'bool' = False,
validate: 'str | None' = None, )
-> 'DataFrame'

728x90
반응형
'AI > Pandas' 카테고리의 다른 글
| Ch07. 깔끔한 데이터 (0) | 2022.09.28 |
|---|---|
| Ch06. 누락값 처리하기 (0) | 2022.09.28 |
| Ch04. 그래프 그리기 (0) | 2022.09.27 |
| Ch03. 판다스 데이터 프레임과 시리즈 (0) | 2022.09.26 |
| 판다스 정리 (0) | 2022.09.26 |
'AI/Pandas' Related Articles
more




Comments