
BASHA TECH
2. Reinforcement Learning - CartPole 예제 본문
728x90
Imports
import os
import math
import random
import numpy as np
import pandas as pd
from pylab import plt, mpl
plt.style.use('seaborn')
mpl.rcParams['savefig.dpi'] = 300
mpl.rcParams['font.family'] = 'serif'
np.set_printoptions(precision=4, suppress=True)
os.environ['PYTHONHASHSEED'] = '0'Cartpole Environment
import gym
print(gym.__version__)=> 0.26.2 version
# 고정된 시드값을 가진 환경 객체
# 카트폴에는 환경, 상태, 행위 등이 다 정의 되어 있는 상태다.
env = gym.make('CartPole-v0')
# 카트폴은 한번의 action마다 보상을 준다. 연속적인 action에 대한 보상이 아님.
# => 그래서 엄밀히 말하면 강화학습이 아님. 현재에 대한 보상 + 미래에 대한 보상이 동반 되어야하기 때문.# env.seed(100)
env.action_space.seed(100) # action_space : 행위 공간 => 이걸 만들어야함.# 최대값과 최소값을 가진 관측 공간
env.observation_spaceenv.observation_space.low.astype(np.float16)=> 최소값
env.observation_space.high.astype(np.float16)=> 최대값
state = env.reset() # 환경 재설정state # 초기 상태 : ([카트 위치, 카트 속도, 폴 각도, 폴 끝 속도], {}) => 전체가 tuple로 나온다
# array를 뽑으려고 indexing 해야함.=> state가 이렇게 2분류로 나누어져서 나옴.

state[0]# 행위 공간
env.action_space # 이산 변수env.action_space.n # space.n => 갯수# 행위 공간에서 무작위로 선택한 행위
env.action_space.sample() # sample method를 만들어야 함. action_space까지.
# 이건 cartpole의 구조여서 개인적으로 환경을 만들어서 강화학습을 만들어야한다.env.action_space.sample()# 무작위로 행위가 선택된 것이다.
a = env.action_space.sample()
a# 무작위 행위에 기반한 스텝
# state : 다음 상태, reward : 행동을 했을 때의 보상, done : 게임의 종료 여부(T/F)
state, reward, done, _ , _ = env.step(a)
# 새로운 환경 상태 및 보상, 성공/실패, 추가정보
state, reward, done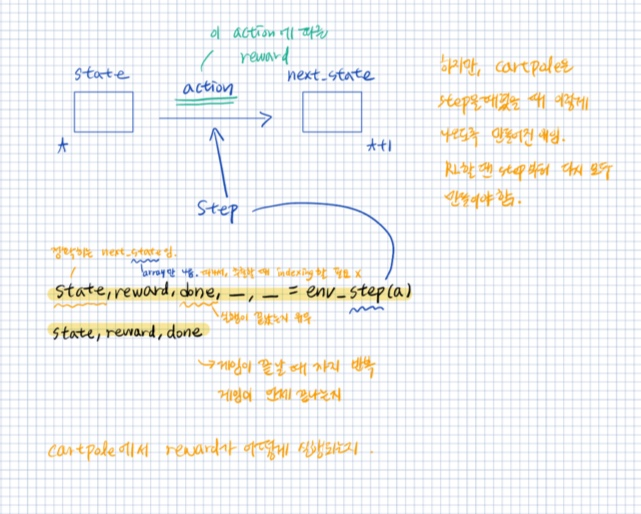
- done=False인 한 에이전트의 게임은 끝나지 않고 또 다른 행위를 선택할 수 있다.
=> 따라서 done = True면, 게임 끝.
- 에이전트(Player)가 연속 200스텝하여 200점의 보상을 얻으면(1스텝당 1점) 게임이 성공하게 된다.
=> 200 연속 스텝했다는 것은 reward가 200이 된다는 뜻. (1step에 1reward니까.) , 200동안 견뎠다는 얘기.
- 폴이 특정한 각도에 다다라 부딪히면 실패하게 된다. (ex. 11번째에서 부딪혔다면, reward는 10)
- 성공이나 실패를 하게 되면 done=True가 된다.
- 가장 간단한 에이전트는 완전히 무작위로 움직이는 에이전트다.
- 어떤 상태가 되든 에이전트는 무작위로 행위를 선택한다.
- 아래 코드는 에이전트가 도달할 수 있는 스텝의 수는 운에 맡기게 된다. (지금은 학습 하는 것이 아님 랜덤하게 돌리는 것) 정책을 업데이트하는 형태의 어떠한 학습도 이루어지지 않는다. (=> 따라서 지금은 엄밀히 말해, 강화학습이 아님)
=> 만약, trading 쪽으로 간다면 cartpole과 다르게 reward를 어떻게 상승시킬 건지 생각해봐야함. cartpole은 0을 유지하는 것이 목적이니까.
env.reset() # 게임 재시작 (한 게임만)
for e in range(1, 200): # 200번 안에 끝나야 함. # 1 episode
a = env.action_space.sample() # 1) 무작위 행위 정책
state, reward, done, _, _ = env.step(a) # 2) 한 스텝 전진
# 다음단계, 보상, 성공/실패 가 뜬다.
print(f'step={e:2d} | state={state} | action={a} | reward={reward}')
if done and (e + 1) < 200: # 3) 200 스템 이내에 실패
# 해당 조건이 실패일 때(done=True), Failed 문장이 뜨면서 반복문 종료 됨.
# done이 True => 조건1. 보상이 200이 되기, 조건2. 200이 되기전에 부딛히기
print('*** FAILED ***')
break

랜덤하기 때문에 결과가 조금씩 다를 수 있는데, 거의 대부분 Failed 뜸. Success 뜨면 대박 럭키.
done=> True : 게임 끝.
728x90
반응형
'AI > Reinforcement Learning' 카테고리의 다른 글
| 5. Reinforcement Learning - Q Learning (0) | 2022.11.23 |
|---|---|
| 4. Reinforcement Learning - 신경망 에이전트 사용 (1) | 2022.11.23 |
| 3. Reinforcement Learning - 몬테카를로 에이전트 (0) | 2022.11.23 |
| 1. Reinforcement Learning - RL의 정의 (0) | 2022.11.22 |
'AI/Reinforcement Learning' Related Articles
more




Comments